









федеральное государственное бюджетное образовательное учреждение высшего образования «Ижевский государственный технический университет имени М.Т. Калашникова» (кафедра "Водоснабжение и водоподготовка" Ижевского государственного технического университета имени М.Т. Калашникова., Доцент)
Ижевск, Удмуртская республика, Россия
УДК 004.043 на структуру данных
В статье рассматриваются вопросы разработки информационных систем управления, поддержки принятия решений и моделирования для производственных процессов в учреждениях пенитенциарной системы. Обозначена проблема недостаточной изученности данных производственного и трудового сектора как с научной точки зрения, так и с позиции разработки нового программного обеспечения и практического применения. Было установлено, что первыми шагами к решению вышеприведенных проблем будут – грамотная структуризация данных и выделение ключевых параметров эффективности. Представление данных в виде множеств и изучение взаимодействия между ними – может явиться хорошим решением для поставленных проблем. Таким образом, в работе была поставлена задача определения ключевых параметров эффективности трудового сектора пенитенциарной системы, а в качестве инструментов для решения поставленной задачи – были рассмотрены принципы теории множеств. Кроме того, для решения поставленной задачи использовались такие созданные ранее разработки как система индексации и программный комплекс для сбора статистических данных. В результате проведенного исследования, были определены правила, а также соотношения, которые можно использовать для определения ключевых параметров эффективности и разработки информационной системы, а также для создания более ориентированных на практическое применение баз данных с более улучшенной структуризацией.
ключевые параметры эффективности, трудовой сектор, пенитенциарная система, теория множеств
Введение
На данный момент для мониторинга в организации производств и управления трудовой деятельностью спецконтингента в уголовно-исполнительной системе Российской Федерации разработан набор утвержденных статистических отчетов. Они позволяют в долгосрочной перспективе вести учет важных параметров и показателей для предприятий и трудовых ресурсов [1]. За многолетний период в учреждениях пенитенциарной системы накоплены достаточно объемные статистические базы данных. Однако, существует ряд проблем.
Во-первых, учтенные данные малоизучены с позиций разработки статистических прогнозов, а также создания и применения систем поддержки принятия решений и управления. Во-вторых, существующие базы данных нередко не связаны между собой, несмотря на наличие сопоставимых параметров [2]. Одной из первых ступеней в решении поставленных проблем будет грамотное структурирование данных: разбиение данных на группы (классы), изучение взаимодействие между группами и выделение ключевых параметров, которые влияют на эффективность производства [3], [4] – что является основой в разработке практически любой системы управления. Применение принципов объектно-ориентированного подхода [5], а также реляционной теории [6] и теории множеств [7] – может явиться хорошим решением для проблемы классификации и сопоставления данных. Таким образом, в качестве цели исследования выступало исследование возможностей применения основ теории множеств для разработки ключевых параметров эффективности трудового сектора пенитенциарной системы.
1. Методы сбора информации, формирование данных для исследования. В работе, для решения представленной задачи, были собраны статистические данные при помощи разработанного ранее программного комплекса «Стат.Оператор» [8], применена разработанная ранее система индексации данных [9], сбор дополнительной актуальной информации проводился на основе программных комплексов «Стат.Проект» и «Стат.Аналитик» [10], [11]. Были рассмотрены актуальные и общепринятые подходы на основе теории множеств [7] и реляционной теории [6], исходя из возможности дальнейшего применения в разработке баз данных и реализации на языках программирования [12]. Формирование множеств также проводилось исходя из существующих приказов: Приказ ФСИН России №754 от 30.08.2019, Приказ ФСИН России №1033 от 12.11.2019, Приказ ФСИН России №661 от 15.09.2020, Приказ ФСИН России от 01.08.2014 № 398.
Исходя из представленной ранее системы индексации данных [9], а также имеющейся статистической информации, все исследуемые параметры для трудового сектора можно представить в виде множеств:
 , (1)
, (1)
где: m=1 – отчет о трудовой адаптации осужденных, m=3 – отчет о производственной и экономической деятельности, связанной с привлечением осужденных к труду, m=4 – сведения о социально-значимых заболеваниях, m=5 – отчет о среднем профессиональном образовании и профессиональном обучении, p - номер раздела в представленных формах учета (в зависимости от m), o – номер исследуемого параметра.
В зависимости от выбора m будут меняться и значения p, o. Для каждого параметра X возможно сделать срезы Y. Согласно приведенной системе индексации данных [9], для (1) будут справедливы срезы Yu,v (2-5):
 , (2)
, (2)
 , (3)
, (3)
 , (4)
, (4)

где: u=1 – срез по учреждениям в рамках производственной и экономической деятельности пенитенциарной системы; u=3 – срез по учреждениям, исполняющим уголовные наказания в виде лишения свободы, СИЗО и характеристике содержащихся в них лиц; u=4 – срез для учреждений исходя из анализа социально-значимых заболеваний; u=5 – разрез для учреждений исходя из данных о среднем профессиональном образовании.
Далее, рассмотрим разделение данных (1) на классы. Здесь, наиболее рациональным могло быть разделение на классы по m, однако, исследуя имеющуюся информацию – это решение оказывается не совсем верным, так как для одного определенного m можно обозначить сразу несколько классов исходя из p. Рассмотрим далее данный вопрос более подробно, а также рассмотрим сами классы.
2. Распределение данных по классам. Согласно имеющимся данным (1-5) здесь можно выделить классы: «Характеристика трудовых ресурсов», «Уровень заработной платы и нормирования труда», «Общая характеристика спецконтингента», «Здоровье и медицинское обеспечение».
Класс «Характеристика трудовых ресурсов». Сюда можно отнести (6):
 , (6)
, (6)
возможность сделать срезы по  и
и  будет следующая:
будет следующая:
 , (7)
, (7)
 . (8)
. (8)
Класс «Уровень заработной платы и нормирования труда». Здесь можно выделить (9):
 , (9)
, (9)
присутствует лишь один возможный срез – , т.е. для данного класса будет справедливо (10):
 .(10)
.(10)
Класс «Общая характеристика спецконтингента». Характеризуется (11):
 , (11)
, (11)
и возможность сделать срезы в рамках (12):
 .(12)
.(12)
Класс «Здоровье и медицинское обеспечение». Здесь можно выделить (13):
 , (13)
, (13)
для которого возможно сделать срезы (14):
 . (14)
. (14)
В данном классе, в отличии от предыдущих, отсутствует суммирующее значение. Поэтому, был введен дополнительный индекс Yu=4,v=9, для которого справедливо (15) (это было сделано, для того чтоб можно было сопоставить данный класс с другими более полноценно):
 , (15)
, (15)
поэтому, одно из определенных ранее условий (4) теперь изменилось (16):
 , (16)
, (16)
и соответственно уже будет справедливо (17):
 , (17)
, (17)
далее рассмотрим класс, который характерен для параметров, которые отражают статистические данные по численности лиц, получающих среднее профессиональное образование и профессиональное обучение.
Класс «Профессиональное образование и обучение». Характеризуется следующим множеством (18):
 , (18)
, (18)
здесь присутствует разрез только для учреждений (19):
 . (19)
. (19)
Таким образом, представленные данные можно разделить и структурировать на классы, создать правила по проведению срезов Y. Данные правила – являются важной ступенью в разработке информационной системы. Здесь, следует отметить, что можно также создавать и временные срезы (например, за определенный месяц в течении несколько лет), однако, этот раздел исследования следует рассматривать отдельно [13].
Существует также возможность исследовать и другие данные и рассмотреть большее количество классов. Однако, это будет выходить за рамки поставленной ранее задачи исследования. При разработке информационных систем управления производственного и трудового сектора пенитенциарной системы в первую очередь следует рассмотреть класс «Трудовые ресурсы», другие же классы (в этом конкретном случае) будут являться второстепенными. Однако, при этом, будут оказывать непосредственное влияние на качество трудовых ресурсов. А значит, UML-диаграмму классов можно построить следующим образом (рисунок 1).
Также можно выделить неявный класс, использование которого позволит более достоверно исследовать информацию по спецконтингенту: другими словами, вести расчеты не в фактических значениях, а в относительных. Таким образом, можно выделить класс «Общая (среднесписочная) численность спецконтингента». Данный класс характеризуется среднесписочными или общими значениями по численности спецконтингента для любого из рассматриваемых . Использовать данный класс следует вкупе с ранее перечисленными. Рассмотрим более подробно правила его использования.
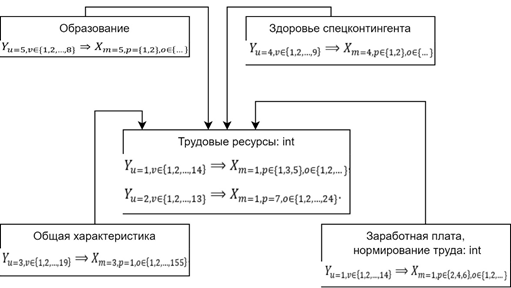
Рис. 1. UML-диаграмма классов трудового сектора
Fig. 1. UML class diagram of the labor sector
В зависимости от m здесь могут быть использованы разные среднесписочные характеристики спецконтингента. Так, для m=1 будет справедливо использовать  (если расчеты ведутся с учетом количества лиц находящихся в СИЗО т.е. с учетом
(если расчеты ведутся с учетом количества лиц находящихся в СИЗО т.е. с учетом  ) или
) или  (только для осужденных т.е. без ). Для m=3 справедливо использовать
(только для осужденных т.е. без ). Для m=3 справедливо использовать  , для m=4 следует использовать
, для m=4 следует использовать  , для m=5 можно использовать данные аналогично m=1 т.е. (если расчеты ведутся с учетом количества лиц находящихся в СИЗО т.е. с учетом
, для m=5 можно использовать данные аналогично m=1 т.е. (если расчеты ведутся с учетом количества лиц находящихся в СИЗО т.е. с учетом  ) или (только для осужденных т.е. без ). UML-диаграмму классов в этом случае можно представить следующим образом.
) или (только для осужденных т.е. без ). UML-диаграмму классов в этом случае можно представить следующим образом.
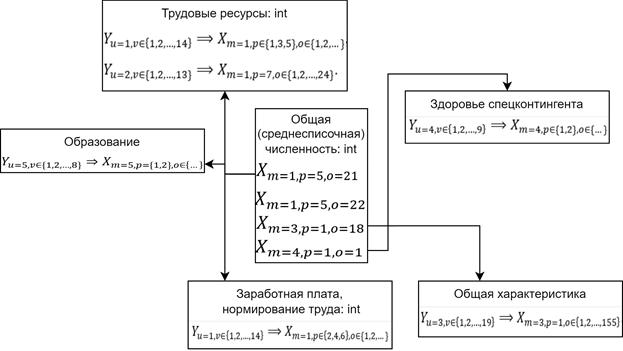
Рис. 2. Влияние класса «Общая (среднесписочная) численность» на рассмотренные ранее классы
Fig. 2. The influence of the class "Total (average) number" on the classes considered earlier
Таким образом, у нас выделен ряд параметров, которые влияют (прямо или косвенно) на остальные. И для которых имеется связь «один ко многим». Благодаря данному классу можно разработать ключевые параметры эффективности (KPI), использование которых позволит более достоверно оценивать и принимать дальнейшие решении при управлении производственным сектором пенитенциарной системы.
3. Разработка KPI на основе классов. KPI (key performance parameters) – ключевые параметры эффективности [3], [4]. KPI могут быть сформированы исходя из структуры данных и взаимодействия параметров между собой. В первую очередь, для разработки KPI, был определен ряд параметров, которые напрямую влияют на остальные. Ими являются параметры класса «Общая (среднесписочная) численность». Например: если рассматриваем  , то практически все параметры здесь будут зависеть от общей среднесписочной численности т.е. и ; если исследование ведется для
, то практически все параметры здесь будут зависеть от общей среднесписочной численности т.е. и ; если исследование ведется для  (только спецконтингент), то здесь следует вести расчеты ориентируясь на ; если рассматриваем
(только спецконтингент), то здесь следует вести расчеты ориентируясь на ; если рассматриваем  , то . Другими словами, для сопоставления данных внутри классов и между классами – можно также разработать ряд условий.
, то . Другими словами, для сопоставления данных внутри классов и между классами – можно также разработать ряд условий.
1. Доля не привлекаемых к труду по особым причинам, уклонение от работы (work avoidance (WA)):
если рассматривать с позиции возмещения причиненного ущерба (compensation for damage (CFD)), то (20):
 , (20)
, (20)
если рассматриваем данные непосредственно по составу трудовых ресурсов (что будет более интересно для поставленных задач) (21):
 , (21)
, (21)
в целом, формирование общего фактического значения не привлечения к труду будет (22):
 ,(22)
,(22)
здесь также можно выделить разные виды отклонения от работы, например:
по состоянию здоровья (23):
 , (23)
, (23)
необоснованный отказ от работы (24):
 (24)
(24)
и другие (рассчитываются аналогичным путем).
Также следует рассматривать среднюю долю привлеченных к труду от общей среднесписочной численности проходящих трудовую адаптацию (т.е. количество реально трудящихся на данный момент (current employees (CE))) (25):
 , (25)
, (25)
а также долю проходящих трудовую адаптацию в целом от среднесписочного числа спецконтингента (workers labor adaptation(WLA)):
 . (26)
. (26)
Немаловажным KPI для производственного процесса является выработка (количество продукции на одного работника) [3]. Расчет на одного человека (productivity per person(PVP)) можно представить следующим образом (27):
 , (27)
, (27)
также будет значимой и выработка в расчете на проходящих трудовую адаптацию в целом (28):
 . (28)
. (28)
а также можно сделать расчет по времени:
если рассматриваем человеко-дни (productivity per time (days) (PPT(D))) за рассматриваемы период то (29):
 . (29)
. (29)
если рассматриваем человеко-часы (productivity per time (hours) (PPT(H))):
 (30)
(30)
Следует также рассмотреть специфику спецконтингента. Здесь можно отметить следующие KPI (при этом разделение на мужчин и женщин среди спецконтингента при этом не рассматривалось):
наиболее вероятная судимость (статья) (criminal record(CR)):
 при
при  , (31)
, (31)
наиболее вероятный возраст (32):
 при
при  , (32)
, (32)
наиболее вероятный срок лишения свободы (term of imprisonment(TOI)) (33):
 при
при  , (33)
, (33)
тяжесть преступления (gravity of the crime (GC)) (34):
 при
при  , (34)
, (34)
доля лиц осужденных при особо опасном рецидиве (Relapse (Rel)) (35):
 , (35)
, (35)
Для параметров, которые связаны с состоянием здоровья, следует вести расчет по общему среднесписочному значению (а не только по трудоустроенным т.к. распространение заболеваний касается абсолютно всего спецконтингента), в итоге:
заболеваемость в целом (morbidity (morb)) (36):
 , (36)
, (36)
при этом следует рассмотреть отдельные социально-значимые заболевания:
доля наркозависимых будет определяться по формуле (drug dependent (DD)) (37):
 , (37)
, (37)
доля лиц с алкогольной зависимостью (alcohol dependent (AD)) (38):
 , (38)
, (38)
доля лиц с диагнозом «ВИЧ» (HIV) (39):
 , (39)
, (39)
доля лиц с гепатитами B,C (HBC):
 , (40)
, (40)
при этом могут быть случаи когда (41):
 (41)
(41)
а также следует учитывать другие немаловажные параметры, например такие как количество случаев суицида (suicide cases (SC)) (42):
 , (42)
, (42)
несчастные случаи на производстве с летальным исходом (industrial accident (IA)) (43):
 , (43)
, (43)
и в целом смертность (mort) (44):
 , (44)
, (44)
Таким образом, были определены некоторые KPI, которые могут оказывать существенное влияние на производственные процессы. В качестве дальнейшего продолжения приведенного исследования может явиться непосредственно разработка базы данных и информационной системы по учету, анализу и прогнозированию KPI. На сегодняшний день, существует достаточно большое количество инструментов для их реализации.
4. Дальнейшая реализация: использование баз данных и ORM
Использование баз данных является неотъемлемой частью в разработке практически любой информационной системы. Рассмотрим наиболее популярные решения, которые существуют и которые применимы к существующей задаче на сегодняшний день [14].
MySQL [15] и PostgreSQL [16] – это две популярные реляционные базы данных с открытым исходным кодом, которые часто используются веб-разработчиками и предприятиями для хранения, управления и доступа к данным. Обе системы предлагают широкий набор функций, но имеют различия в производительности, масштабируемости и функциональности.
Рассмотрим более подробно использование MySQL [15].
1. Веб-приложения: MySQL широко используется веб-разработчиками для хранения данных веб-приложений, таких как блоги, интернет-магазины, форумы и другие.
2. Небольшие и средние проекты: MySQL обеспечивает хорошую производительность для небольших и средних проектов, особенно при ограниченных ресурсах.
3. Простые приложения с небольшой нагрузкой: MySQL хорошо подходит для приложений с небольшой нагрузкой, где требуется простая структура базы данных и относительно небольшое количество одновременных запросов.
Особенности использования PostgreSQL [16].
1. Большие и сложные проекты: PostgreSQL обладает богатым набором функциональных возможностей, поддерживает сложные типы данных и обработку больших объемов данных, что делает его хорошим выбором для крупных и сложных проектов.
2. Безопасность и целостность данных: PostgreSQL предлагает более расширенные механизмы безопасности и контроля целостности данных, что делает его предпочтительным выбором для приложений, где важны надежность и безопасность данных.
3. Геоинформационные системы (GIS): PostgreSQL имеет встроенную поддержку для геоинформационных данных и предоставляет возможности для работы с пространственными объектами и запросами.
4. Аналитика и обработка данных: Благодаря возможностям работы с большими объемами данных и поддержке расширений для аналитики и обработки данных, PostgreSQL широко используется в аналитических системах и хранилищах данных.
В целом, выбор между MySQL и PostgreSQL зависит от конкретных требований проекта, включая его масштаб, требования к производительности, безопасности данных и функциональности.
Еще одной популярной базой данных является SQLite [17]. SQLite – это компактная и самодостаточная реляционная база данных, которая не требует сервера и обычно сохраняет всю свою базу данных в единственном файле на диске. Она часто используется в мобильных приложениях, настольных приложениях, встроенных системах и других сценариях, где требуется небольшой объем данных или нет необходимости в масштабируемости и многопользовательской поддержке. Вот несколько случаев использования SQLite [17]:
1. Мобильные приложения: SQLite широко используется в мобильных приложениях для хранения локальных данных, таких как пользовательские настройки, кэшированные данные, журналы действий и т.д.
2. Встроенные системы и устройства: SQLite часто используется во встроенных системах и устройствах, где требуется небольшой размер, простота использования и отсутствие необходимости в сервере базы данных.
3. Настольные приложения: SQLite может быть использован в настольных приложениях для хранения данных, таких как офлайн-записные книжки, менеджеры паролей, учетные записи клиентов и т.д.
4. Прототипирование и тестирование: SQLite может быть полезен для создания прототипов и тестирования приложений, поскольку не требует установки и настройки сервера базы данных.
5. Веб-разработка: в некоторых случаях SQLite может быть полезным для разработки веб-приложений, особенно на ранних стадиях разработки или для небольших проектов с ограниченной нагрузкой.
SQLite обеспечивает простой и быстрый способ управления небольшими объемами данных без необходимости в настройке и управлении сервером базы данных. Однако он не подходит для проектов, требующих масштабируемости, высокой производительности или многопользовательской поддержки, поскольку он не предоставляет некоторых функций, которые предлагают серверные базы данных, такие как PostgreSQL или MySQL.
Одной из популярных технологий для реализации систем управления базами данных является ORM (Object-Relational Mapping) [18]. ORM – это техника программирования, которая позволяет разработчикам работать с базами данных с использованием объектно-ориентированного подхода. Она устраняет необходимость написания прямых SQL-запросов, а вместо этого позволяет взаимодействовать с базой данных через объекты программного кода. Некоторые преимущества и особенности использования ORM [18]:
1. Абстракция базы данных: ORM предоставляет абстракцию базы данных, скрывая детали реализации и позволяя разработчикам работать с базой данных на уровне объектов.
2. Уменьшение дублирования кода: ORM упрощает доступ к данным и сокращает объем кода, который разработчики должны написать для взаимодействия с базой данных.
3. Повышение производительности: ORM-фреймворки обычно предоставляют механизмы для оптимизации запросов к базе данных, что может повысить производительность приложения.
4. Поддержка различных баз данных: Многие ORM-фреймворки позволяют разработчикам использовать один и тот же код для работы с различными типами баз данных.
5. Объектно-ориентированный подход: ORM позволяет использовать объектно-ориентированный подход к проектированию приложений, что делает код более понятным и поддерживаемым.
6. Уменьшение уязвимостей безопасности: ORM может помочь в предотвращении инъекций SQL и других уязвимостей безопасности, так как он обычно предоставляет механизмы для безопасного выполнения запросов к базе данных.
Некоторые известные ORM-фреймворки в мире программирования включают [18] Django ORM для языка Python, Hibernate для языка Java, Entity Framework для языка C#, SQLAlchemy для языка Python, Sequelize для языка JavaScript (Node.js) и многие другие.
Однако использование ORM может иметь и некоторые недостатки, такие как потеря производительности из-за дополнительных слоев абстракции и более сложное управление запросами к базе данных. Всегда важно выбирать подходящий инструмент в зависимости от требований вашего проекта и опыта команды разработчиков. В целом полученные данные подтверждают мнение о том, что для анализа эффективности отдельных структур пенитенциарной системы эффективно применение теории множеств и объектно-ориентированного подхода [19].
Заключение. В приведенной работе представлены возможные пути решения некоторых проблем, которые связаны с разработкой информационных систем для производственного сектора пенитенциарной системы. Было установлено, что исследование статистической информации, которая ведется в пенитенциарной системе, с позиции основ теории множеств и реляционной теории позволит лучше структурировать данные, выделить наиболее значимые параметры.
Исходя из проведенного анализа, были определены ограничивающие условия для срезов данных, а также выделено шесть классов. Было определено, что использование фактических значений (учет которых ведется на сегодняшний день) – является не совсем верным решением для проведения аналитических расчетов в долгосрочной перспективе. Более приемлемым вариантом будет исследование интересующих параметров исходя из общей (среднесписочной численности). Так, для классов «Трудовые ресурсы» ( ), «Уровень заработной платы и нормирования труда» ( ), «Профессиональное образование и обучение» ( ) расчет данных следует вести исходя из или ; для класса «Общая характеристика спецконтингента» ( ) – исходя из ; для «Здоровье и медицинское обеспечение» ( ) – .
Одной из важных частей в разработке информационной системы является грамотная структуризация данных. Теория множеств и основы реляционной теории, как показано в приведенном исследовании – являются замечательным инструментом для этого. Представленное классовое распределение данных может быть положено в основу разработки KPI, а также может быть использовано при объектно-ориентированном подходе в разработке информационной системы.
1. Пономарёв Д.С., Горохов М.М., Пономарёв С.Б. Обработка форм статистической отчетности Федеральной службы исполнения наказаний на основе методов разведочного анализа данных библиотек языков "Python" и "R" // Вестник Воронежского института ФСИН России. 2023. № 2. С. 106-112.
2. Пономарев Д.С., Горохов М.М., Пономарев С.Б. Медико-социальная адаптация как фактор повышения качества производственно-трудовой деятельности осужденных. Отчет о НИР. ФКУ НИИ ФСИН России, 2023. С. 5-40.
3. Marr B. Key Performance Indicators (KPI): The 75 measures every manager needs to know Financial Times Press, 2012. 347 p. ISBN 9780273750383.
4. Peterson E.T. The Big Book of Key Performance Indicators. Wiley. 2006. 109 p.
5. Althoff С. The Self-Taught Computer Scientist: The Beginner's Guide to Data Structures & Algorithms. Wiley, 1st edition. 2021. 224 p. ISBN 9781119724339.
6. Date C.J. SQL and Relational Theory. O’Reilly. 2010. 474 p. ISBN 9781491941133.
7. Robert R.S. Set Theory and Logic. Dover Publications, Revised ed. edition. 1979. 512 p. ISBN 9780486638294.
8. Свидетельство о государственной регистрации программы для ЭВМ № 2015612855. Стат.Оператор : № 2014663634 : заявл. 26.12.2014 : опубл. 26.02.2015 ; заявитель Федеральное казенное учреждение «Научно-исследовательский институт информационных технологий Федеральной службы исполнения наказаний» (ФКУ НИИИТ ФСИН России). – EDN KHWEMU.
9. Пономарев Д.С. Разработка систем индексации данных для производственно-экономического и трудового секторов пенитенциарной системы // Инженерный вестник Дона. №3 2024. С. 100-108. EDN CAZJLC.
10. Свидетельство о государственной регистрации программы для ЭВМ № 2015612075. Стат.Проект : № 2014663715 : заявл. 26.12.2014 : опубл. 11.02.2015 ; заявитель Федеральное казенное учреждение «Научно-исследовательский институт информационных технологий Федеральной службы исполнения наказаний» (ФКУ НИИИТ ФСИН России). – EDN GHRZEY.
11. Свидетельство о государственной регистрации программы для ЭВМ № 2015612427. Стат.Аналитик : № 2014663636 : заявл. 26.12.2014 : опубл. 18.02.2015 ; заявитель Федеральное казенное учреждение «Научно-исследовательский институт информационных технологий Федеральной службы исполнения наказаний» (ФКУ НИИИТ ФСИН России). – EDN WLOOLP.
12. Lutz M. Learning Python. 5th Edition. Vol.1. O’Reilly, 2019. 832 p. ISBN 9781449355739.
13. Пономарев Д.С. Разработка алгоритмов обработки временных рядов при работе с статистическими отчетными формами производственного сектора пенитенциарной системы // Инженерный вестник Дона. 2024. № 2(110). С. 184-191. EDN FQCEPF.
14. Walter Sh. SQL Quick Start Guide. Clyde Bank technology. 2022. 223 p. ISBN 9781945051838.
15. Nichter D. Efficient MySQL Performance: Best Practices and Techniques. O'Reilly Media; 1st edition. 2022. 335p. ISBN 9781098105044.
16. Obe R., Hsu L. PostgreSQL: Up and Running: A Practical Guide to the Advanced Open Source Database. O'Reilly Media; 3rd edition. 2017. 312 p. ISBN 9781491963364.
17. Kreibich J. Using SQLite: Small. Fast. Reliable. Choose Any Three. O'Reilly Media; 1st edition. 2010. 526 p. ISBN 9781449399641.
18. Halpin T. Object-Role Modeling Fundamentals: A Practical Guide to Data Modeling with ORM. Wiley, First Edition. 2015. 192 p. ISBN 9781634620741.
19. Благодатский Г.А., Горохов М.М., Пономарев С.Б. Системный анализ организационной структуры медицинской службы уголовно-исполнительной системы и управление ее реформированием/ Ижевск: Изд-во ИжГТУ, 2017. 104 с. ISBN 978-5-7526-0775-2.